framework
Fauvel et al. (2020) proposed a performance-explainability analytical framework for benchmarking Machine Learning (ML) models and demonstrated with an application of classification problem. However, there remain opportunities to put performance, explainability, and fairness together to create a framework for benchmarking ML models. The research aims to extend Fauvel et al.’s framework by incorporating explainability for the AI fairness aspect to build a comprehensive framework for evaluating ML models. We evaluate its applicability with classification problems using multiple classifiers. The experimental case study demonstrates the successful application of the performance-explainability-fairness framework to the classification problem. The framework can guide means for improving fairness in machine learning model development and deployment.
Fauvel et al.’s performance-explainability analytical framework uses a set of characteristics that systematize the performance-explainability assessment to evaluate and benchmark ML algorithms. However, there is a gap within the literature regarding its applicability to different classifiers and introducing fairness in addition to performance and explainability when benchmarking ML algorithms for suitability to a particular use case.
The proposed performance-explainability-fairness extended framework (Table 1) is based on the framework proposed by (Fauvel et al., 2020). We extend the framework by adding two fairness characteristics to Fauvel et al.’s framework (Chakrobartty & El-Gayar, 2022). The framework aims to answer the many queries that an end-user may have to make an educated choice based on the recommendations of an ML model. The evaluation characteristics, the questions, and the assessment values are described in Table 1. Table 1 summarizes the framework.
Table 1. Characteristics of the performance-explainability-fairness framework
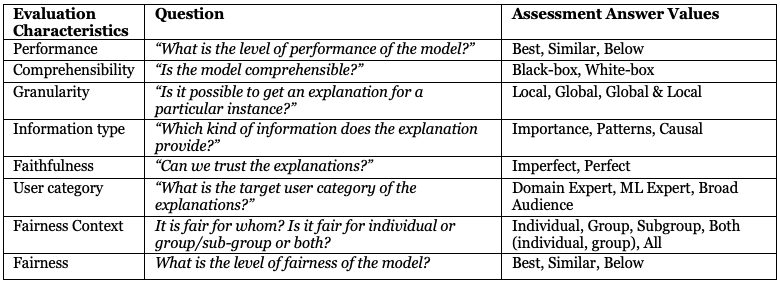
The extended framework addresses the fairness of an ML model. The fairness context evaluation characteristics answer the question, for whom is it fair? It is important to identify the fairness context because while statistical parity-based group fairness equalizes outcomes across protected and non-protected groups, the outcome could still be very unfair from the point of view of an individual (Dwork et al., 2012). Additionally, according to Kearns et al. (2017), for group fairness, a classifier may give the impression that it is fair to each individual group, although it may still seriously violate the fairness criteria on one or more structured subgroups which are specific combinations of protected attribute values defined over all the protected attributes. We consider individual, group (Speicher et al., 2018), sub-group fairness (Kearns et al., 2017, 2019), and a combination of those for assessing the fairness context of the model for which its fairness is measured.
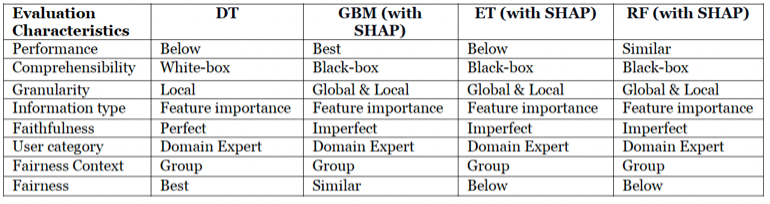
We were successfully able to apply the extended framework to evaluate the default credit classifiers classification problem where four tree bases classifiers Decision Tree (DT), Gradient Boosting Machines (GBM), Extremely random Trees (ET), and Random Forest (RF) based ML models were benchmarked as shown in Table 2. We adopted an open dataset from the University of California Irvine (UCI) ML Repository named “default of credit card clients Data Set” (Yeh 2016) that records customers’ credit card payment history. We used Microsoft’s fairlearn toolkit for analyzing the AI fairness-related metrics. The results are promising.
Table 2. Four different classifiers fairness and performance metrics
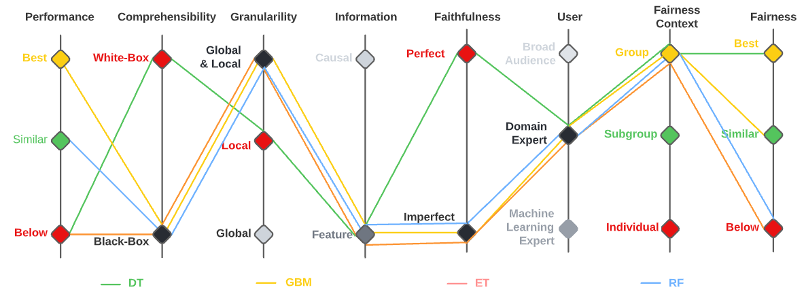
An illustration of the result is also presented in below figure with parallel coordinates plot of the default credit classifiers. Overall, we determine that the GBM model would be the best choice when considering all different characteristics of the performance-explainability-fairness framework as applicable to the default credit score dataset.
Thus, we evaluated the proposed performance-explainability-fairness framework by benchmarking the current state-of the-art default of credit card client’s data classifiers. The proposed framework details a set of characteristics that systematize the performance-explainability-fairness assessment of ML models. The proposed framework can be used to identify ways to improve current machine learning models as well as design new ones.
References
Barredo Arrieta, A., Diaz-Rodriguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., Garcia, S., Gil-Lopez, S., Molina, D., Benjamins, R., Chatila, R., & Herrera, F. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion, 58, 82–115. https://doi.org/10.1016/j.inffus.2019.12.012
Chakrobartty, S., & El-Gayar, O. (2022). Towards a Performance-explainability-fairness Framework for Benchmarking ML Models. AMCIS, 9.
Fauvel, K., Masson, V., & Fromont, É. (2020). A Performance-Explainability Framework to Benchmark Machine Learning Methods: Application to Multivariate Time Series Classifiers. ArXiv:2005.14501 [Cs, Stat]. http://arxiv.org/abs/2005.14501
Holzinger, A., Plass, M., Holzinger, K., Crisan, G. C., Pintea, C.-M., & Palade, V. (2017). A glass-box interactive machine learning approach for solving NP-hard problems with the human-in-the-loop. CoRR, abs/1708.01104. http://arxiv.org/abs/1708.01104
Yeh, I.-C. 2016. “UCI Machine Learning Repository: Default of Credit Card Clients Data Set,” , January 26. (https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients, accessed January 23, 2022).